Exploring the Landscape: Architectures Powering LLM-Driven Applications
Ready with your favorite snack🍇🍪? Architecture Snacks is about having a short break and learning something new. Let's dive in!

Hey there! Today, I'm not going to dive into the nitty-gritty of terms like Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM), Transformers, or Convolutional Neural Networks (CNNs). Yes, they're often called types of Machine Learning (ML) architecture, but I like to think of them as Language Model Learning (LLM) algorithms. Instead, I want to cover today what I consider to be general architecture types of applications powered by LLM - think Chatbots, Sentiment Analysis Tools, Text Summarization, and similar AI products that have been gaining popularity over the past year and a half. We are going to look into 3 main architectures that might be chosen as a basic for your LLM driven application and appropriate use cases for each.
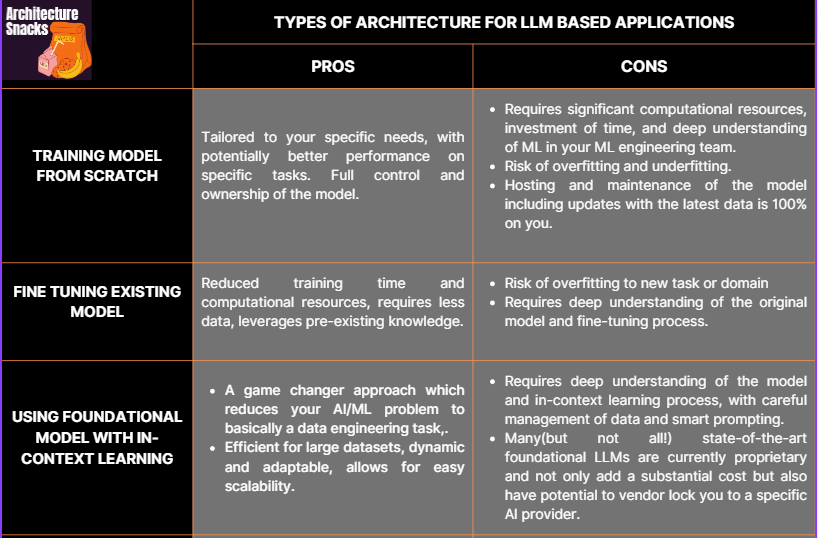
1. Training Model from Scratch
Training your own Language Model Learning (LLM) model from scratch can be a good idea when you have a large, domain-specific dataset that is significantly different from the data the pre-trained models were trained on. This approach allows you to tailor the model to your specific needs and can potentially lead to better performance on your specific tasks.
However, training an LLM model from scratch also has its downsides. It requires a significant amount of computational resources and time, which can be costly. It also requires a deep understanding of machine learning and language modeling, as you'll need to handle tasks such as data preprocessing, model architecture selection, and hyperparameter tuning. Furthermore, you'll need to manage the risks of overfitting and underfitting, which can lead to poor model performance.
In addition, even if you have a large, domain-specific dataset, pre-trained models might still perform better. These models are trained on a diverse range of data, which can help them generalize better to unseen data. They also benefit from the collective knowledge and resources of the machine learning community, which can be hard to match with a model trained from scratch.
In summary, while training an LLM model is a complex and resource-intensive process that requires careful consideration. For many applications, fine-tuning a pre-trained model instead may be a more efficient and effective approach.
2. Fine Tuning Existing Model For Your Use Case
Fine-tuning a pre-trained Language Model Learning (LLM) model is a often preferable when you have a specific task that is not covered by the pre-trained model's capabilities, or when you have a domain-specific dataset that is similar to the data the pre-trained model was trained on. This approach allows you to leverage the knowledge the model has already learned, while customizing it to better suit your specific needs.
The advantages of fine-tuning a pre-trained model include reduced training time and computational resources compared to training a model from scratch, as the model has already learned general language patterns. It also requires less data, as the model only needs to learn the specifics of your task or domain, not the entire language.
However, fine-tuning a pre-trained model also has its challenges. It requires a careful balance to avoid overfitting to the new task or domain, which can lead to poor generalization to unseen data. It also requires a deep understanding of the original model and the fine-tuning process, as improper fine-tuning can lead to unexpected model behavior or performance degradation. In addition, while fine-tuning can improve performance on your specific task or domain, it may not always be necessary. Pre-trained models are designed to be versatile and may already perform well on your task without fine-tuning. It might well be that you can just focus instead on providing your domain specific context to the pre-trained foundational model and get the results you need via smart prompting.
3. Using Foundational Model With In Context Learning
In-context learning is a cool method that uses something called Language Model Learning (LLM) to guide behavior using smart prompts and relying on private "contextual" data. It's super helpful when dealing with big datasets, as it only sends the most important documents with each LLM prompt. The process is as simple as 1-2-3: prepare the data, create and retrieve the prompts, and then execute and infer from the prompts. This way, a tricky AI problem becomes a more manageable data engineering problem, making it a breeze to handle and add new data in real time. Building on the simplicity of in-context learning, the process allows for easy scalability. As new data is added or existing data is changed, the system adapts in real time via use of smart prompts.
The process of smart prompting involves understanding the task at hand, the data available, and the capabilities of the LLM model. The prompts are then designed to guide the model towards the desired output. This could involve providing examples of the desired output, giving explicit instructions, or conditioning the model on specific pieces of information. However, smart prompting requires a deep understanding of the model and the task, as improper prompting can lead to unexpected model behavior or performance degradation. It also requires careful management of data to ensure the most relevant documents are sent with each LLM.
Overall, in-context learning is a dynamic, efficient, and adaptable approach to data management which is nowadays becomes the most popular starting point for ramping up AI product for many teams. Foundational models empower solo developers to construct remarkable AI applications in just a few days, outperforming the supervised machine learning projects that previously required large teams and months of work.
Summary
Please find below a one stop table with main points on available types of architectures for LLM-based applications.